
Logs - Por que, boas práticas, e recomendações

Por que logging é importante?
Informação de logging é importante para entender o comportamento de uma aplicação e para entender problemas em diferentes cenários. No tempo de vida de uma aplicação, ela irá eventualmente cair, algum servidor irá ficar indisponível, usuários podem reclamar de bugs “randômicos”, ou algum cliente pode perceber que alguma informação está faltando sem que haja alguma dica do porquê que essa informação está ausente. Esses são alguns exemplos de cenários onde é necessário entender o comportamento da aplicação através do seu ciclo de vida, rastrear informações através das validações de QA e cenários de incidente, e outras situações possíveis. Esses são motivos pelos quais logs das soluções devem ser projetados, implementados, e testados.
Considerando todas essas questões relacionadas com a importância dos logs é necessário definir para a aplicação o que, como, e quando logar e até como extrair informação significativa dos logs. Isso traz a necessidade de definir a estrutura das mensagens de log. Essa necessidade existe para ser possível extrair a informação necessária (na maioria das vezes com a ajuda de alguma ferramenta).

Outra questão válida mencionar é que as mensagens de log precisam ser lançadas pelo menos em cada camada da arquitetura com informação significa e com contexto. Ter pelo menos um registro de log por request/result em cada camada da aplicação permite prover contexto preciso sobre o que o usuário estava fazendo quando um erro em específico ou situação ocorreu.
Uma vez que isso está definido para a estrutura das mensagens de log, o próximo passo é definir o que logar e como. As mensagens de log da aplicação precisam informar
sobre erros (para usá-los em diagnósticos), mas também informação útil sobre requisições com sucesso para ter uma ideia clara de como os usuários utilizam a aplicação.
Nesse sentido, é possível conseguir através das mensagens de log relacionadas com esses objetivos a informação que queremos destacar.
Logging levels
O uso de uma boa estratégia de logging precisa considerar o uso adequado da classificação das mensagens de log. A estratégia da classificação das mensagens de log é essencial para evitar “ruído” quando procuramos informação e procuramos possíveis evidências para avaliar um problema ou comportamento da aplicação. Os principais benefícios disto são que quando um problema ocorre é possível ter informação com contexto para analisar.
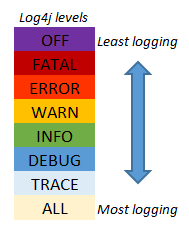
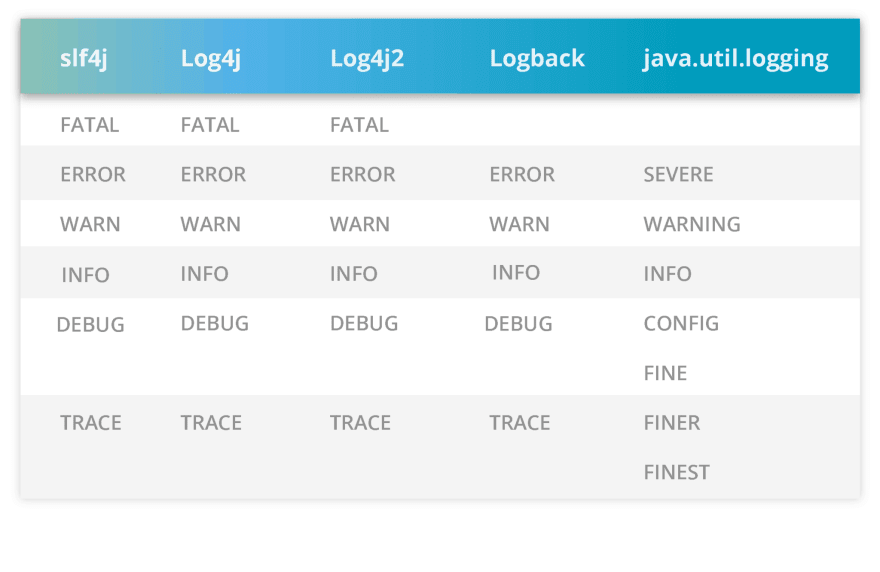
Existem frameworks para lidar com mensagens de log nas mais diferentes languages de programação, e a definição sobre a classificação das mensagens de log pode variar sutilmente entre suas implementações. Mas elas seguem o mesmo propósito semântico. O exemplo abaixo mostra como elas são usadas para alguns dos frameworks Java.
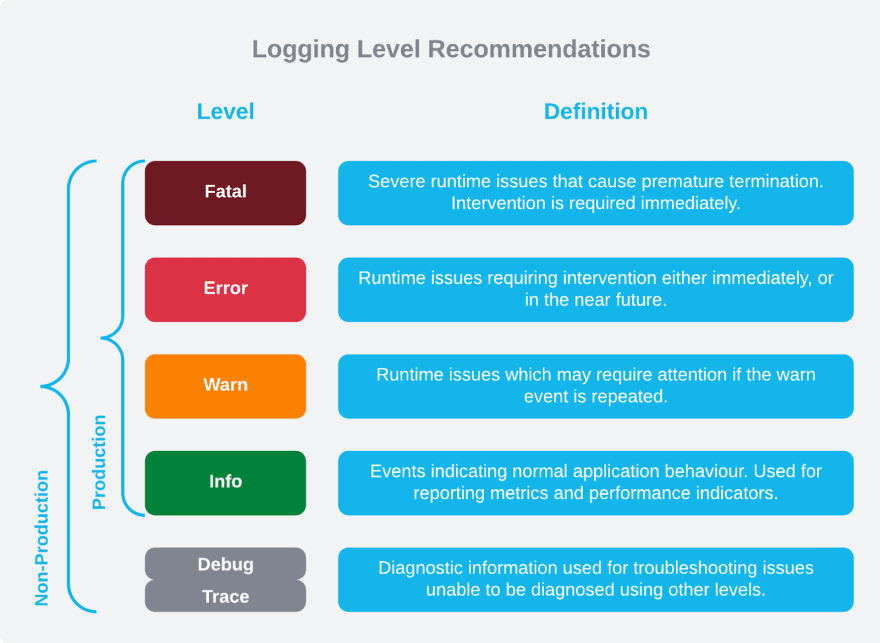
A classificação das mensagens de log tem recomendações de uso bem definidas para as mais diversas situações:
Recomendações de boas práticas
Conforme as razões apresentadas sobre práticas de logging de aplicações, existem algumas boas práticas e recomendações a serem seguidas para permitir que as mensagens de log sejam significativas e úteis.
Boas práticas gerais
-
Configurar o logging level via configuração externa: a configuração da classificação das mensagens de log deve sempre ser uma tarefa feita em runtime. Isso permite ação rápida diagnóstico de problemas e análise de situações sem precisar parar a aplicação.
-
Configuração padrão do nível das mensagens de log por ambientes: Para o ambiente de produção é interessante ter o nível padrão de log como “Information”. Isso vai permitir que mensagens com os níveis Fatal, Error, Warning, e Information serão apresentadas. Enquanto os níveis de log Debug e Trace serão evitadas. Ambientes que precisem de informação mais detalhada podem ter a configuração padrão do nível de log configuradas como debug ou trace.
-
A configuração do nível de log adequada é importante para evitar ruído: Informação de log de aplicação com o nível de log adequado evita erros de interpretação em relação a dados que representam um problema e dados que representam comportamento da aplicação:
-
Usar os níveis de informação Warning e Information adequadamente: Warning deve ser usado para informar situações que não são erros, mas não são um comportamento normal. Information deve ser usado para fluxo normal da aplicação quando algo importante deve ser comunicado.
-
Logar falhas catastróficas utilizando Critical/Fatal: Quando existe um erro irrecuperável durante a inicialização da aplicação ou execução, logar utilizando o nível de mensagem Critical. Ferramentas podem usar essa informação para emitir alertas.
-
Navegar durante a execução do código com nível de mensagem Debug: Quando a aplicação não está se comportando adequadamente para ter uma visibilidade melhorada sobre o que está acontecendo. O bom uso do nível Debug de mensagem pode trazer mais detalhes sobre o que está ocorrendo.
-
Inspect variables using the Trace log level: The use of trace log level to write the values of variables, parameters, and settings to the logs for inspection can help you when the debug log level isn’t enough. This mimics the behavior of inspecting the contents of variables with the debugger attached.
-
-
Nunca logar informações de identificação pessoal ou senhas: É extremamente importante devido a GDPR, CCPA, LGPD, e outras leis relacionadas com privacidade e segurança.
Boas práticas para logar eventos
-
Use pares de chave/valor claros: ferramentas utilizam valor dos campos para realizar suas pesquisas, visando criar dados estruturados sobre o texto gerado.
-
Crie eventos que pessoas possam ler: encoding complexos que possam demandar pesquisas e tornem a informação do evento ilegível.
-
Use timestamps para cada evento: a data hora correta é algo crítico para a sequência dos eventos, para debugging, analytics, e tratar transações.
-
Use correlation IDs para rastrear operações: Correlation ID (também conhecido como Transit ID) é um identificador único anexado a requisições e mensagens que permitem referenciar uma transação em particular ou cadeia de eventos. São úteis em debugging e avaliação de transações no sistema, sendo passado entre diferentes máquinas, redes, e serviços.
-
Evite logar informação binária: Não ajuda a ler o que está acontecendo através do log de eventos, e também não funciona bem quando as ferramentas estão indexando informação.
-
Use formato de dados estruturado: São legíveis por humanos e automações, e pode-se fazer parse da informação na maioria das linguagens de programação, ou por navegadores. Isso ajuda ferramentas e pesquisa de logs ao avaliar logs de eventos.
-
Identificar a origem (classe, função, ou arquivo): Útil para entender onde está o problema.
Boas práticas operacionais
-
Logar em arquivos localmente: se a escrita de logs é feita em ambiente local, é possível fazer um buffer local e não é bloqueada a escrita de log se houver uma queda de rede.
-
Usar ferramentas para streaming e monitoração de logs: ferramentas podem coletar informação dos logs e enviar essa informação para indexadores. Possibilitam trabalhar bem com os grandes volumes de informação gerados pelas atividades de logging.
-
Use políticas de rotação e retenção: logs podem ocupar muito espaço. Boas estratégias de rotação pode ajudar a decidir quando destruir ou fazer backup dos logs (se necessário). Especialmente considerando cenários para soluções cloud onde armazenamento é importante para os custos.
-
Colete eventos de todas as fontes possíveis: quanto mais dados são capturados, mais visibilidade se tem. Alguns exemplos de possíveis fontes:
- Logs de aplicação;
- Logs de Base de Dados;
- Logs de rede;
- Arquivos de configuração;
- Dados de performance.
Ferramentas para tratar informação dos logs
Sem ter ferramentas para lidar com informação dos logs, a quantidade de dados gerada pela atividade dos logs perde sentido. Além de que em um cenário com diversas fontes e instâncias de aplicações distribuídas, e diversos serviços que essas aplicações fazem integração, essas ferramentas são úteis para relacionar as informações que vêm das diferentes fontes. Cada uma dessas fontes formatam e armazenam logs à sua própria maneira, tornando realmente difícil achar dados úteis.
As ferramentas de logging disponíveis atualmente fazem streaming das mensagens de log e centralizam seu acesso, permitindo pesquisá-las e agregá-las e transformando os dados gerados em informação útil. Tem diversos exemplos de ferramentas de logging hoje em dia, mas segue abaixo o exemplo de duas delas. A primeira imagem é um exemplo utilizando splunk, e a imagem seguinte é um exemplo utilizando a stack da Elastic:
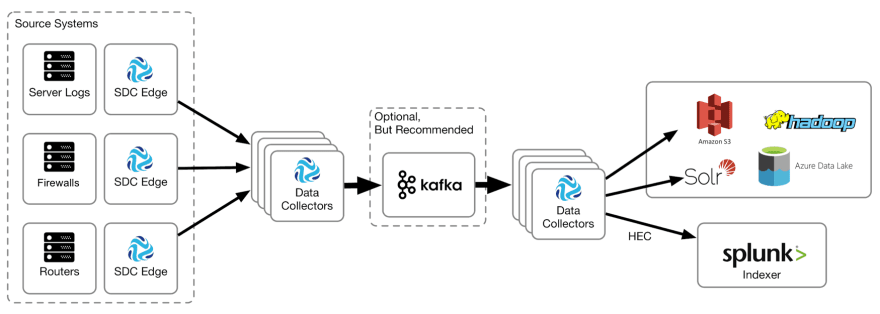
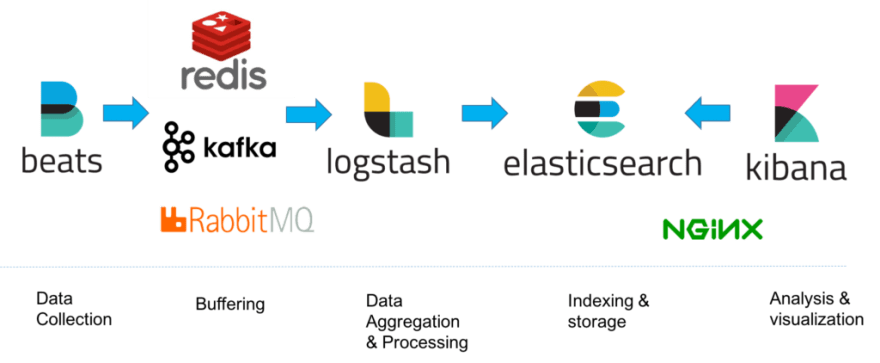
Essas ferramentas usam coletores para buscar as mensagens de log e armazenam a informação em repositórios onde a informação é indexada. Quando os coletores pegam a informação, eles analisam a estrutura do log para processar seus dados antes do armazenamento. Uma vez que as mensagens de log estão armazenadas e indexadas é possível pesquisar informação, criar gráficos e alertas através da inferface dessas ferramentas. Seguem alguns exemplos das buscas feitas na interface dessas ferramentas. As interfaces são das ferramentas Splunk, Graylog, e Kibana.
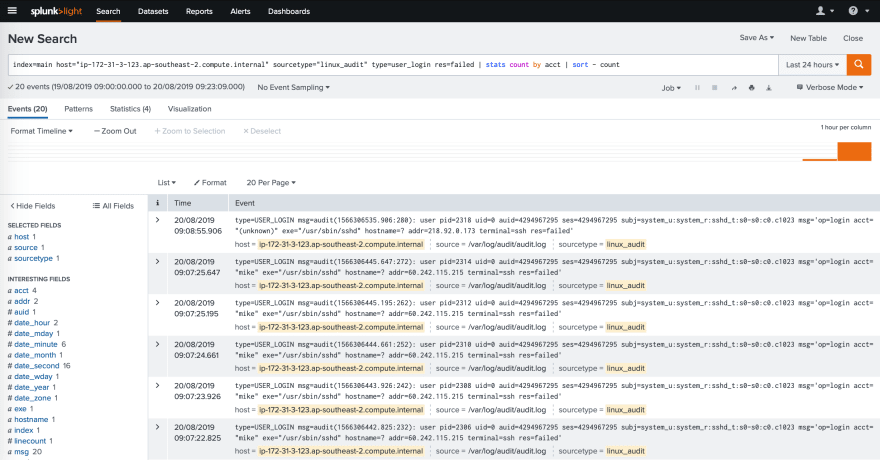
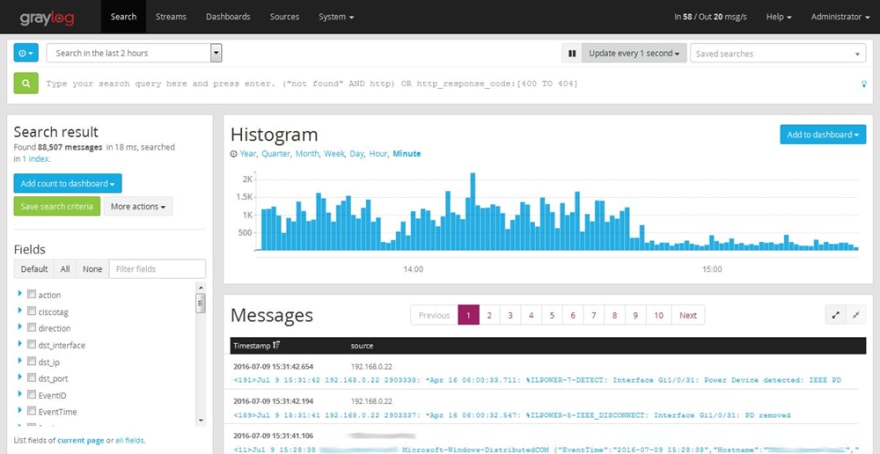
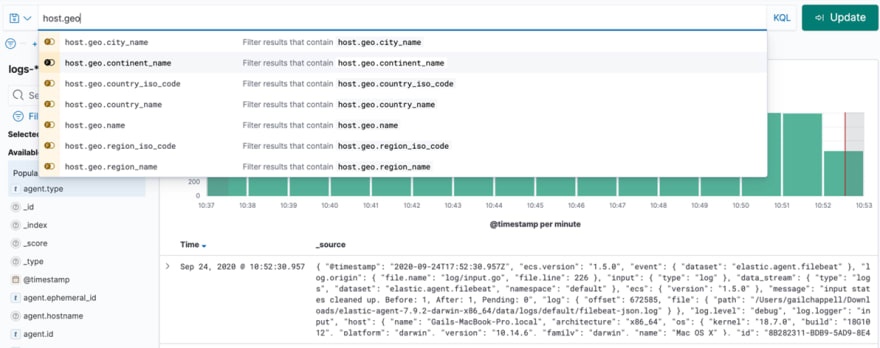
Como é possível ver, essas ferramentas têm funcionalidades interessantes relacionadas coma atividade de logging. Isso traz uma boa razão para trabalhar com as mensagens de log seguindo uma estrutura bem definida, boas práticas, e recomendações. Isso permite fazer processamento da informação dos logs, relacionar, e manipular por ferramentas de forma que elas se tornem realmente úteis.