
Um breve exemplo sobre comunicação via mensagem com Kafka

Esse artigo surgiu como uma ideia quando eu estava revisando conteúdos que eu já havia estudado, e com os quais já trabalhei. Como precisava estudar alguns outros tópicos relacionados ao uso de Kafka em soluções de aplicação tive a ideia de compartilhar um pouco de informação. É um artigo de nível bem iniciante. Não sou um especialista em Kafka, mas já trabalhei com soluções que utilizavam o modelo de comunicação assíncrona e sistemas de mensageria. Baseado nisso, tentarei explorar o assunto cobrindo os seguintes items:
- Trazer algumas considerações sobre cenários de solução de comunicação síncrona e assíncrona;
- Exemplo de uso do Kafka no contexto de um cenário de comunicação assíncrona (implementação básica de producer e consumer).
A ideia não é explorar os trade-offs sobre Kafka como tecnologia ou plataforma. Então, não haverá aprofundamento nessa direção. Sobre o tema o
AWS link relacionado com o serviço Amazon Managed Streaming para Apache Kafka tem algumas comparações
quando compara Kafka e RabbitMQ. É possível ter uma ideia sobre as diferenças quando Kafka é comparado com ferramentas de solução de mensageria.
Comunicação síncrona e assíncrona
Nesses anos em que tenho trabalho com TI é possível ver como uma situação comum cenários onde desenvolvedores tem dificuldade de distinguir sobre quando usar comunicação síncrona e assíncrona em cenários de solução. Muitas vezes é possível perceber a falta da avaliação de alguns detalhes dos requisitos para projetar a solução a ser implementada, ou uma avaliação errada sobre quais poderiam ser a abordagem apropriada a ser aplicada a um problema. É de grande ajuda o entendimento das principais características de ambas as abordagens quando se está fazendo essa avaliação.
Integração Síncrona vs. Assíncrona
Em resumo, o principal ponto de destingue a necessidade de comunicação síncrona e assíncrona será a necessidade de precisar ou não receber uma resposta de uma requisição para poder continuar o processamento de alguma outra coisa. Quando a resposta é necessária para processar algo, o cenário de comunicação síncrona será geralmente a melhor abordagem. Quando num cenário de comunicação for possível ou necessário desacoplar o comportamento do produtor da informação do comportamento do consumidor de forma que a resposta não seja necessária para continuar o processamento de algo, geralmente a abordagem assíncrona será melhor.
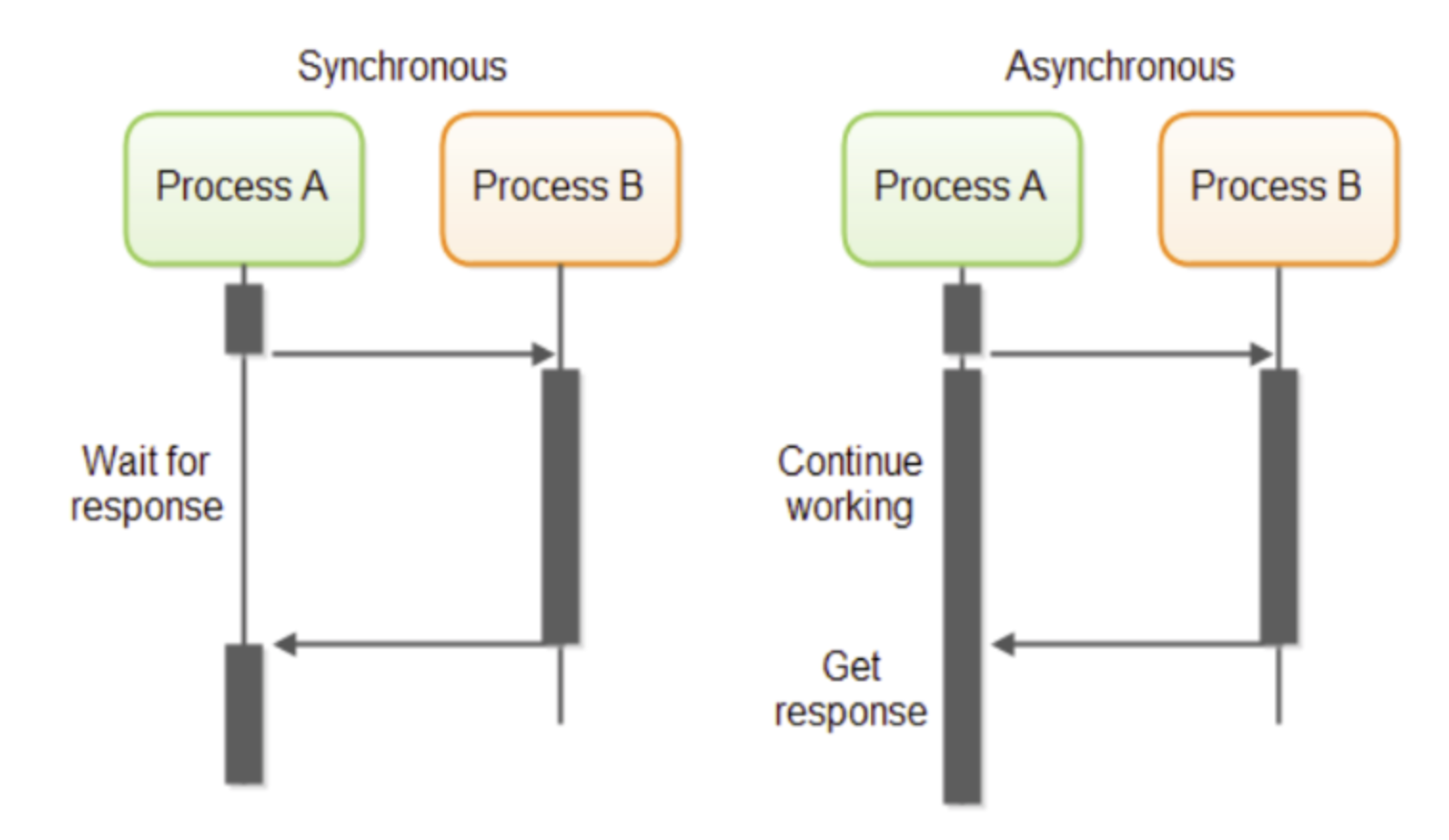
Importante reforçar que não existe bala de prata quando se discute projeto de solução. As escolhas vêm com trade-offs a serem analisados onde a escolha tem pontos positivos e problema a serem tratados, assim como podem existir alguns requisitos que podem invalidar algum candidato à solução. Por exemplo, É possível trabalhar com APIs para um projeto de comunicação assíncrona se a corporação trabalha com uma abordagem API driven. O serviço devolve uma resposta para a requisição com um HTTP status code 202 para informar que algo vai ser processado no futuro. E algum endpoint de callback do cliente pode ser chamado posteriormente quando esse processamento terminar. Mas essa abordagem tem esses trade-offs.
Ao considerar Kafka como um componente em sua solução é possível dizer que a maioria dos casos ele vai se encaixar em um
Enterprise Integration Pattern relacionado à Messaging Patterns. Com Kafka é possível
combinar dois modelos de mensageria (filas e publish-subscribe) para prover os benefícios chave para cada consumidor. Mais detalhes podem ser encontrados nesse
AWS link sobre Amazon Managed Streaming para Apache Kafka.
Exemplo de Producer e Consumer usando Kafka
Apache Kafka é uma tecnologia de streaming de dados real-time capaz de lidar com trilhões de eventos por dia. É comumente utilizada para construir real-time streaming data pipelines e aplicações event-driven. Provê uma plataforma distribuída, com high-throughput, low-latency, e tolerância a falhas, para lidar com feeds de dados real-time - conhecidos como eventos. Mais detalhes podem ser encontrados em Apache Kafka official page.
A principal ideia é mostrar um exemplo com Kafka para envio e consumo de mensagens em uma comunicação assíncrona. Para ilustrar um producer e um consumer foram criadas
2 aplicações Kotlin utilizando Kafka como exemplo em que Tweets são consumidos baseado em algum parâmetro e sendo o evento salvo em um repositório ElasticSearh
que permita pesquisar o conteúdo dos Tweets. Em uma aplicação de real-time isso poderia ser usado para acompanhar em tempo real assuntos ou temas que são
trend topics por qualquer motivo em específico. Mais detalhes sobre a implementação podem ser verificados aqui.
Nesse exemplo não foi profundamente explorado o conjunto de configurações do consumer ou configurações do producer. A ideia principal era ressaltar um exemplo de implementação para produzir mensagens/eventos para um Kafka e consumi-los. A fonte de informação são os Tweets filtrados. Todos os componentes estão relacionados em uma estrutura docker-compose para facilitar o uso e manusear o exemplo.
Nas aplicações foram criadas configurações de componentes para ter todas as configurações de Kafka para consumers e producers.
@Bean
fun consumerFactory(): ConsumerFactory<String?, Any?> {
val props: MutableMap<String, Any> = HashMap()
props[ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG] = servers
props[ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG] = StringDeserializer::class.java
props[ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG] = StringDeserializer::class.java
props[ConsumerConfig.AUTO_OFFSET_RESET_CONFIG] = "earliest"
return DefaultKafkaConsumerFactory(props)
}
@Bean
fun kafkaListenerContainerFactory(): ConcurrentKafkaListenerContainerFactory<String, Any>? {
val factory = ConcurrentKafkaListenerContainerFactory<String, Any>()
factory.consumerFactory = consumerFactory()
factory.containerProperties.ackMode = ContainerProperties.AckMode.MANUAL_IMMEDIATE
factory.containerProperties.isSyncCommits = true;
return factory
}
@Bean
fun producerFactory(): ProducerFactory<String, Any> {
val configProps: MutableMap<String, Any> = HashMap()
configProps[ProducerConfig.BOOTSTRAP_SERVERS_CONFIG] = servers
configProps[ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG] = true
configProps[ProducerConfig.ACKS_CONFIG] = "all"
configProps[ProducerConfig.COMPRESSION_TYPE_CONFIG] = "snappy"
configProps[ProducerConfig.LINGER_MS_CONFIG] = 5
configProps[ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG] = StringSerializer::class.java
configProps[ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG] = StringSerializer::class.java
return DefaultKafkaProducerFactory(configProps)
}
@Bean
fun kafkaTemplate(): KafkaTemplate<String, Any> {
return KafkaTemplate(producerFactory())
}
Uma vez que as mensagens de tweet são objetos JSon grandes não tentei mapeá-los para objetos específicos. Foram serializados como uma String JSon em ambos os lados da comunicação. Os detalhes sobre o consumo das mensagens de tweet estão no seguinte GitHub repository. Após lê-las, é possível publicá-las em um tópico Kafka:
@Component
class KafkaTweetsProducer(
private val kafkaTemplate: KafkaTemplate<String, Any>
) {
companion object {
private val LOGGER = LoggerFactory.getLogger(KafkaTweetsProducer::class.java)
}
fun send(key: String, tweet: String) {
LOGGER.info("Tweet message: {}", tweet)
kafkaTemplate.send("tweets-message-topic", key, tweet)
}
}
O consumer lê o tweet do mesmo modo que ele chega do tópico Kafka para salvar no repositório ElasticSearch:
@Component
class KafkaTweetsConsumer(
private val elasticSearchClient: RestHighLevelClient,
@Value("\${elasticsearch.index}")
private val tweeterIndex: String
) {
companion object {
private val LOGGER = LoggerFactory.getLogger(KafkaTweetsConsumer::class.java)
}
@KafkaListener(topics = ["tweets-message-topic"], groupId = "simple-kotlin-tweets-message-consumer")
fun consume(tweet: String) {
LOGGER.info("got tweet: {}", tweet)
val indexRequest = IndexRequest(tweeterIndex).source(tweet, XContentType.JSON)
val indexResponse = elasticSearchClient.index(indexRequest, RequestOptions.DEFAULT)
LOGGER.info("ElasticSearch id: {}", indexResponse.id)
}
}
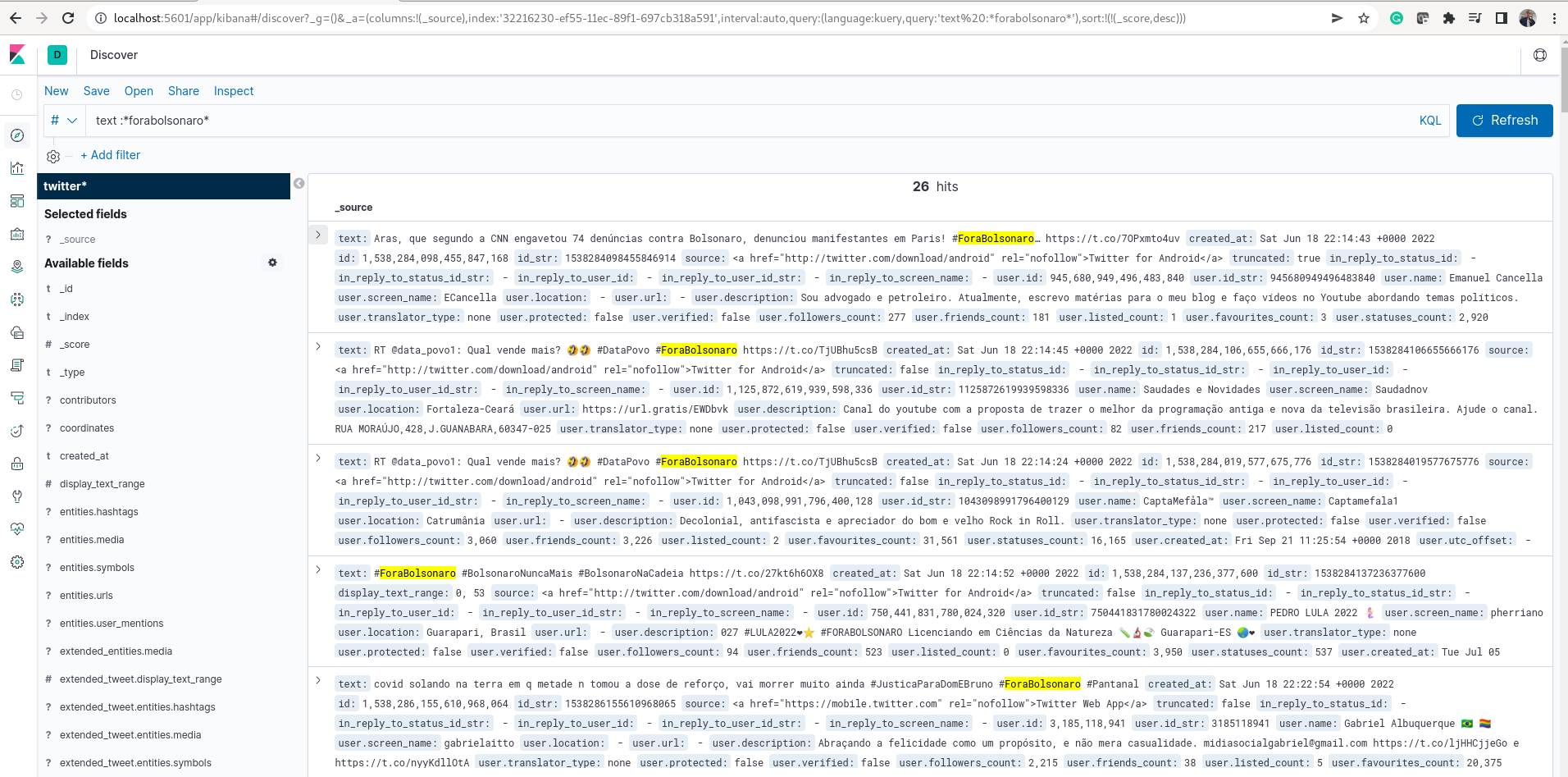
O arquivo README do repositório tem instruções para configurar e rodar o exemplo. O resultado da comunicação entre o producer e consumer pode ser visto em uma interface do Kibana:
Considerações finais
Kafka como ferramenta e tecnologia atende vários use-cases reais poderosos. É uma tecnologia válida de ser explorada para abordagem de microserviços, arquitetura event driven,
de comunicação assíncrona, processamento real time, streaming data, e vários outros cenários. Espero que esse artigo possa ser útil para uma leitura de nível iniciante.
Referencias
Asynchronous Communication; The What, The Why, And The How
Apache Kafka - Fundamentals, Use cases and Trade-Offs
- Dhruvesh Patel: https://dev.to/dhruvesh_patel/apache-kafka-fundamentals-use-cases-and-trade-offs-9e4